A fine-tuned Vision-Language-Action (VLA) policy will pick up the alphabet soup and place it in the basket on demand, then drop the soup off the table when an evaluator shifts the basket five centimeters left. We use activation injection to ask what the policy is doing: inject task A's activations into task B's scene at the action expert, and π0.5 executes task A's motor trajectory in 99.6% of episodes (n = 1,968); X-VLA does so in 99.8%. The injected program is bound to absolute workspace coordinates rather than the visible scene, which mechanistically explains the perturbation brittleness reported in concurrent benchmark work. The same intervention framework applied across six VLAs (π0.5, OpenVLA-OFT, X-VLA, SmolVLA, GR00T N1.5, and ACT as a language-free control) on LIBERO, MetaWorld, SimplerEnv, and ALOHA over 420,000+ rollouts surfaces three further findings: language is encoded by every architecture yet behaviorally ignored when vision uniquely identifies the goal; SAE pooling preference splits along architecture lines (π0.5 per-token, X-VLA mean-pool, SmolVLA indifferent); and pathway specialization replicates wherever expert and VLM pathways are separable. SmolVLA's interleaved fusion attenuates the headline to 52.1% LIBERO override, scoping universality. We release Action Atlas, an interactive feature-exploration platform covering all 520+ trained SAEs and 79 identified concepts.
Per-token Sparse Autoencoders + causal interventions for VLA mechanistic interpretability
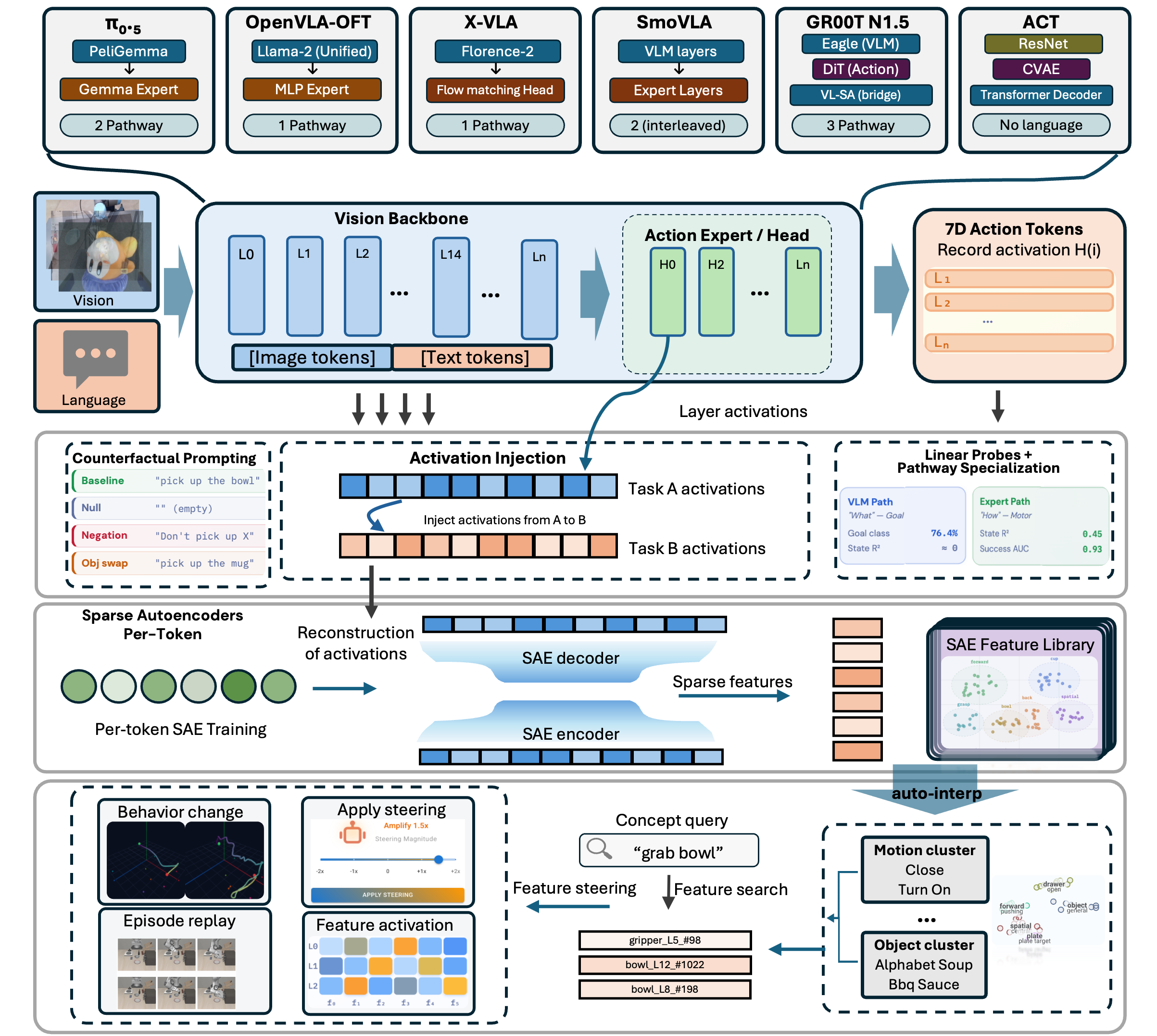
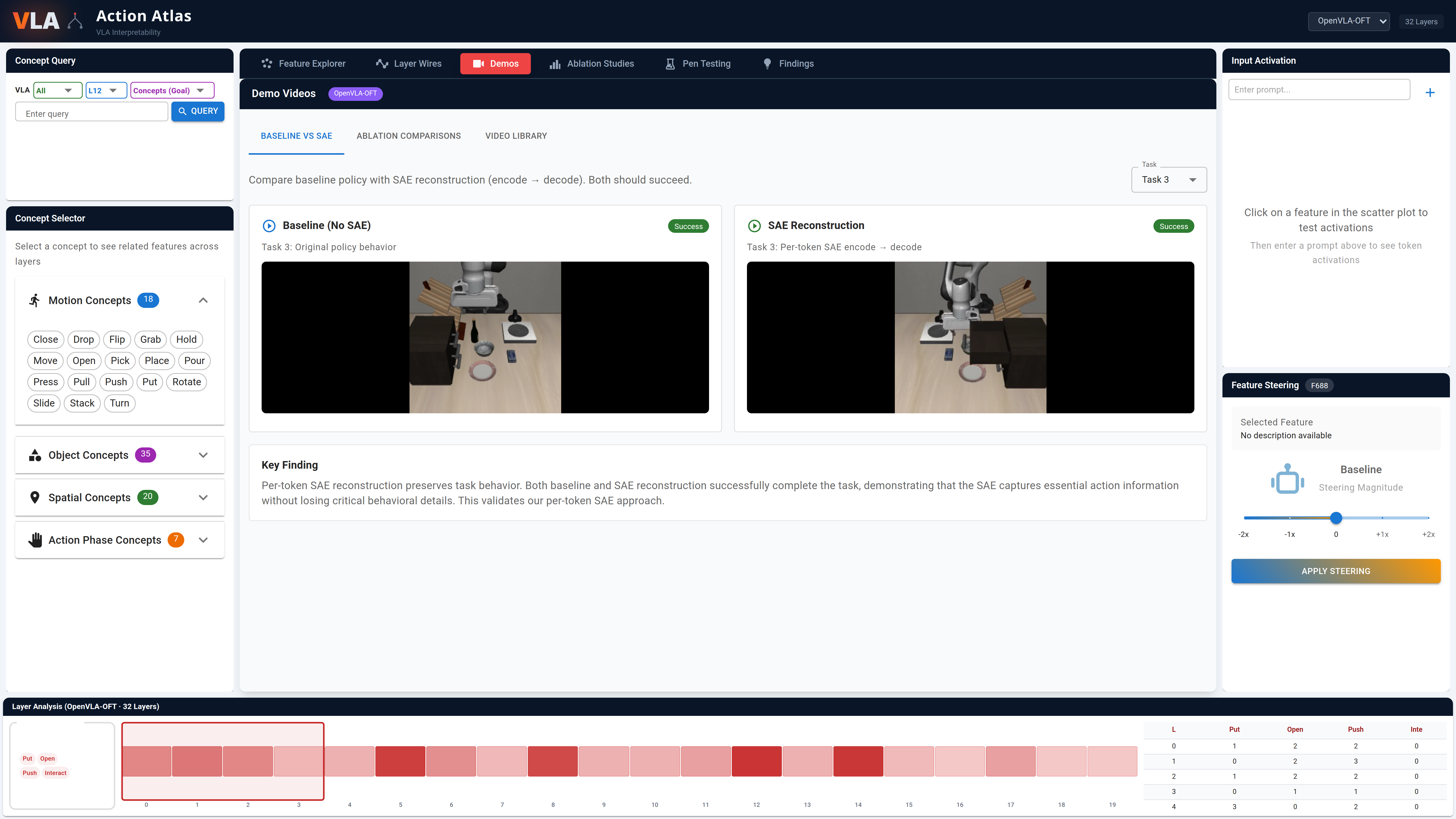
Methodology overview. Top: activations are recorded from VLA backbone and action expert layers during rollout episodes, then replayed under counterfactual conditions (null prompts, cross-task scenes) to establish causal relationships via behavioral change. Middle: per-token SAEs decompose layer activations into sparse features. Bottom: features are clustered, searched, and causally validated through ablation and steering experiments, with results visualized in Action Atlas.
We train 520+ TopK SAEs (k=64) across all six models with 4–8× expansion. Each action token is processed independently to preserve temporal structure. Feature importance is scored via frequency-weighted contrastive selection (Cohen's d × top-k frequency), recovering 79 aligned manipulation concepts.
We test causality with four injection conditions: null injection (correct prompt to empty string), same-scene steering (redirect to alternate targets), cross-task injection (transfer across visual scenes), and random-direction (norm-matched control: 22% source behavior vs. 99.6% directed).
Concept ablation zeros out specific SAE features during live rollouts, while feature steering scales feature activations by α to amplify or suppress encoded behaviors.
Ridge regression probes recover prompt-category labels at > 99% accuracy from the residual stream of every model tested. A projection operator test confirms causality: projecting out the probe direction drops downstream R² to chance.
We test language grounding with 6 prompt variations across 11,226 counterfactual episodes spanning all five language-capable VLAs: baseline, null (empty string), negation, motor commands, object swap, and mid-episode temporal switches. SmolVLA is additionally evaluated across MetaWorld's four difficulty tiers.
A five-step argument across six VLA architectures
Replacing the prompt with an empty string and replaying the image stream from a different episode restores actions to cosine ≥ 0.99 against the original, with rollout success recovering to 14–77% across all six architectures. Zeroing the visual pathway collapses every model to noise.
Cross-task injection rebinds the trajectory, not the goal: π0.5 99.6% (n=1,968), X-VLA 99.8% (n=3,150), OpenVLA-OFT 96.4% (n=1,079, tie-conditional), GR00T 57.0%, SmolVLA 52.1% on LIBERO. A norm-matched random-direction control yields 22%; a vision-only ACT controller produces 0.0% override by construction.
Linear probes recover prompt-category labels at > 99% accuracy: the goal is encoded. Yet on visually unambiguous suites, replacing the prompt does almost nothing: across 3,396 counterfactual episodes, π0.5 / LIBERO-Object yields F(4,3391)=1.23, p=0.247, η²=0.0015. Language matters only when scenes are visually ambiguous.
In all three multi-pathway architectures (π0.5, SmolVLA, GR00T), expert pathways carry the motor program and VLM pathways carry the goal. SmolVLA's expert accounts for 78.6% of cross-task override against 25.6% for the VLM, isolating the bind/select interface to the expert stream.
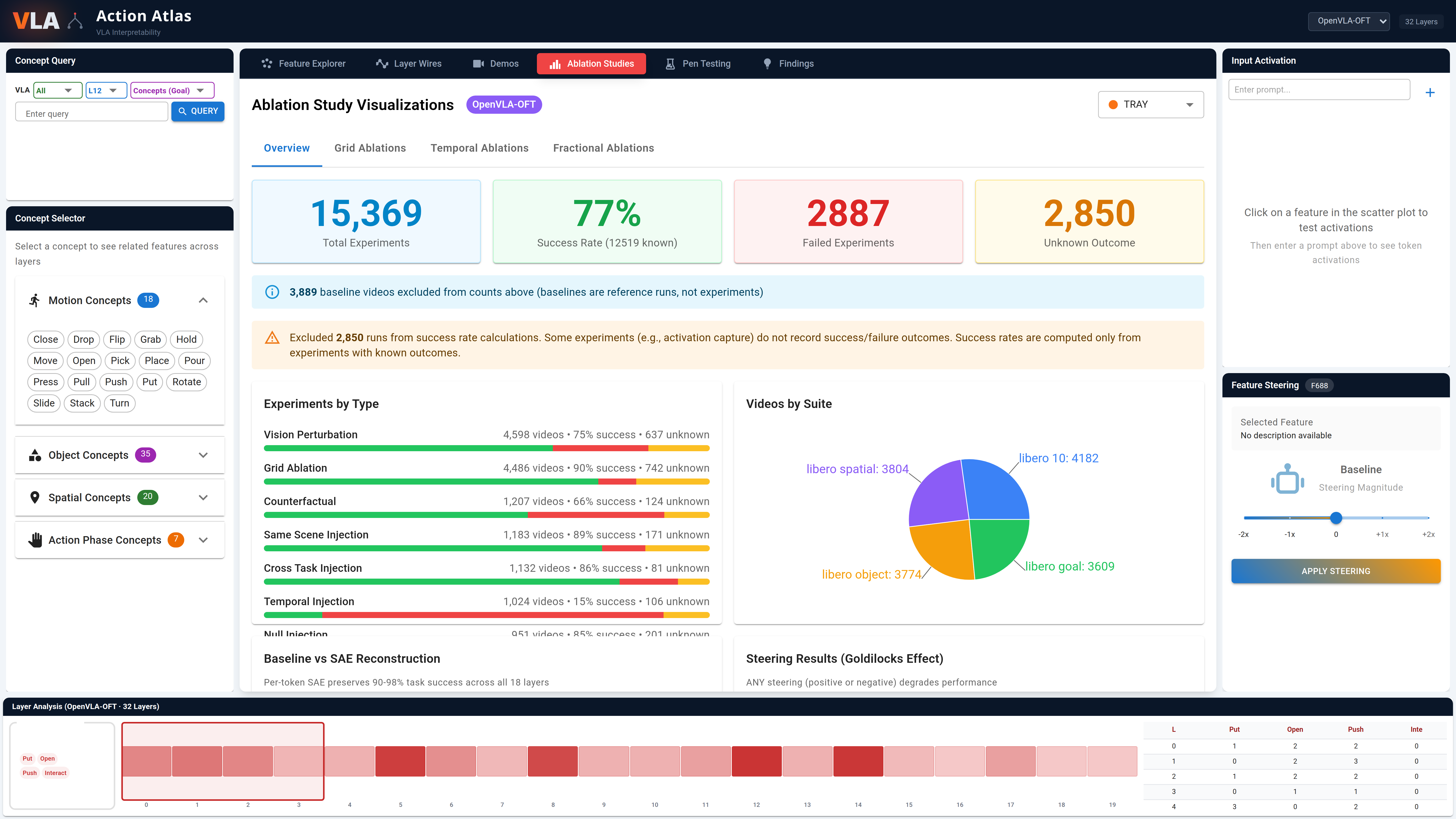
Which pooling preserves rollout fidelity is an architectural property, not a universal VLA property: per-token preserves π0.5 and OpenVLA-OFT, mean-pool suits X-VLA, and SmolVLA is indifferent. Single-feature SAE ablation produces 28–92% zero-effect rates depending on architecture, and causal sensitivity does not follow representation width.
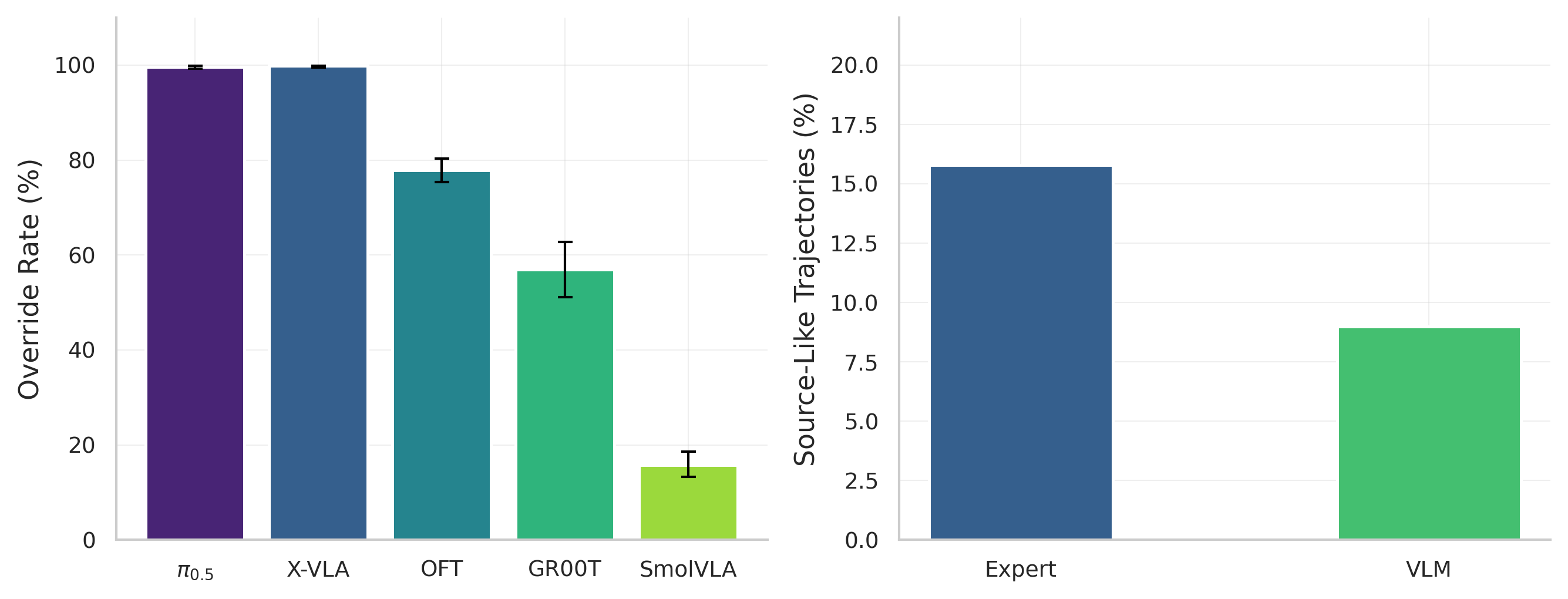
Cross-task injection override rates. π0.5 99.6% (n=1,968) and X-VLA 99.8% (n=3,150) show near-complete source behavior transfer; OpenVLA-OFT 96.4% (n=1,079, tie-conditional; 77.9% tie-inclusive); GR00T 57.0%; SmolVLA 52.1% on LIBERO with strong pathway split (78.6% expert vs. 25.6% VLM). Vision-only ACT control: 0.0%.
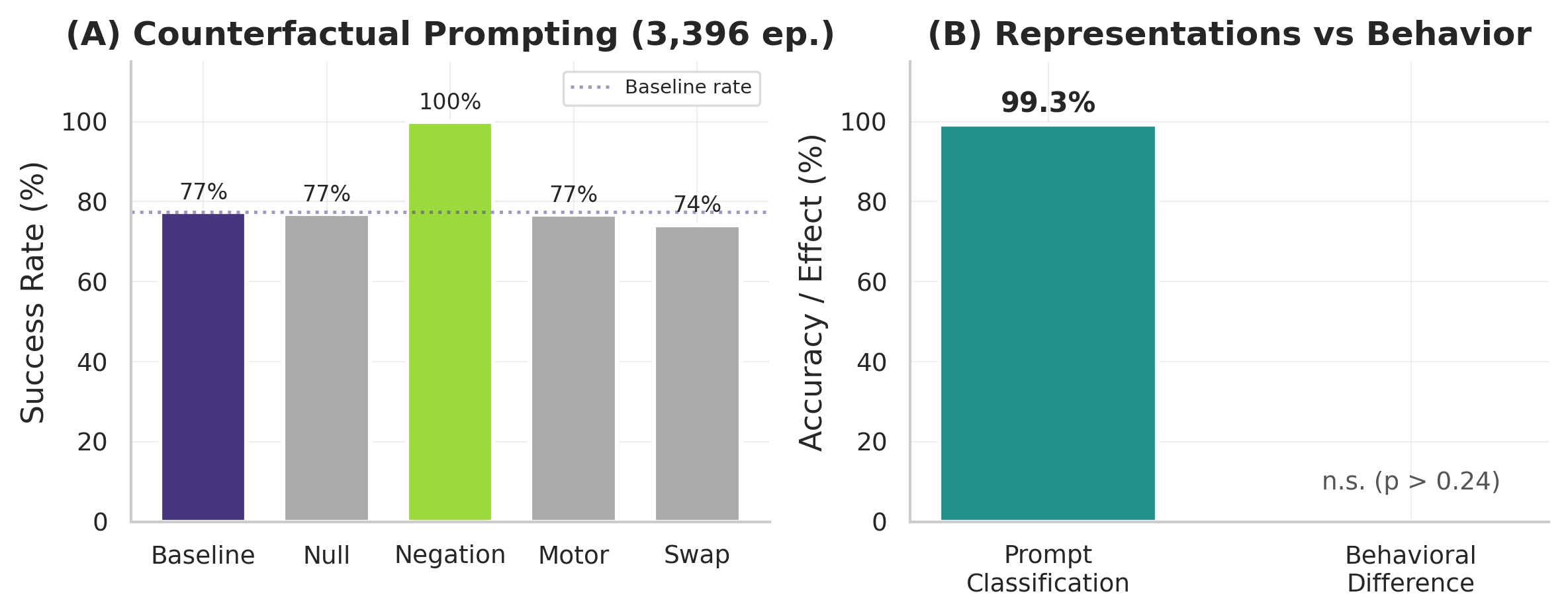
Language is encoded yet behaviorally ignored on visually unambiguous suites. π0.5 / LIBERO-Object across 3,396 counterfactual episodes shows no significant behavioral difference (F(4,3391)=1.23, p=0.247, η²=0.0015), even though layer-17 classifiers distinguish the same prompts at > 99% accuracy.
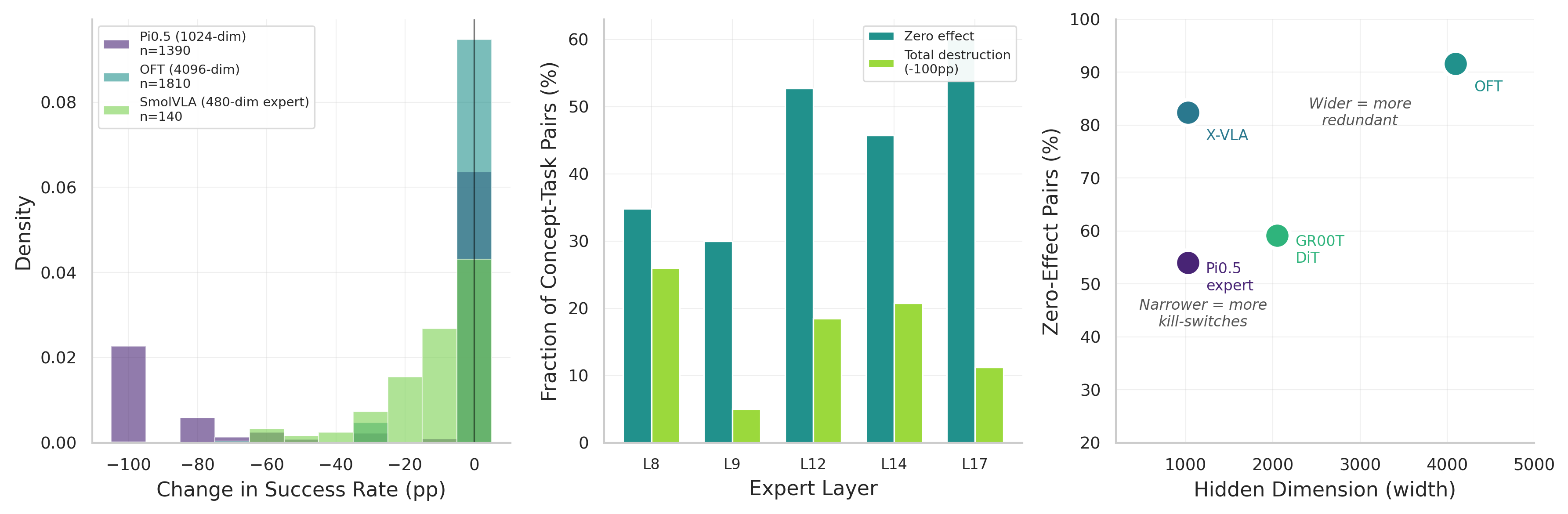
Single-feature concept ablation across five language-capable VLAs. SmolVLA (480-dim expert) is the most sensitive at 28% zero-effect rate; OpenVLA-OFT (4096-dim) and X-VLA (1024-dim) are the most resilient at 92% and 82%. Causal sensitivity does not follow representation width; it is architecture-tied.
| Model | Hidden Dim | Zero-Effect Rate | Destruction Rate | Profile |
|---|---|---|---|---|
| SmolVLA Expert | 480 | 28% | 6.3% | Narrow, most sensitive |
| π0.5 Expert | 1024 | 54% | 14% | Bimodal, kill-switches at L8 |
| GR00T N1.5 | 1536-2048 | 59% | 9.1% | Pathway-dependent (DiT > Eagle) |
| X-VLA | 1024 | 82% | 2.7% | Resilient despite narrow width |
| OpenVLA-OFT | 4096 | 92% | 0.5% | Wide, most resilient |

PUT concept ablation (L8): “Put the cream cheese in the bowl.” Top: baseline picks up cream cheese and places it in the bowl (91 steps). Bottom: with PUT features zeroed, the robot drops the cream cheese into the bowl, knocking it over (300 steps, task failure).
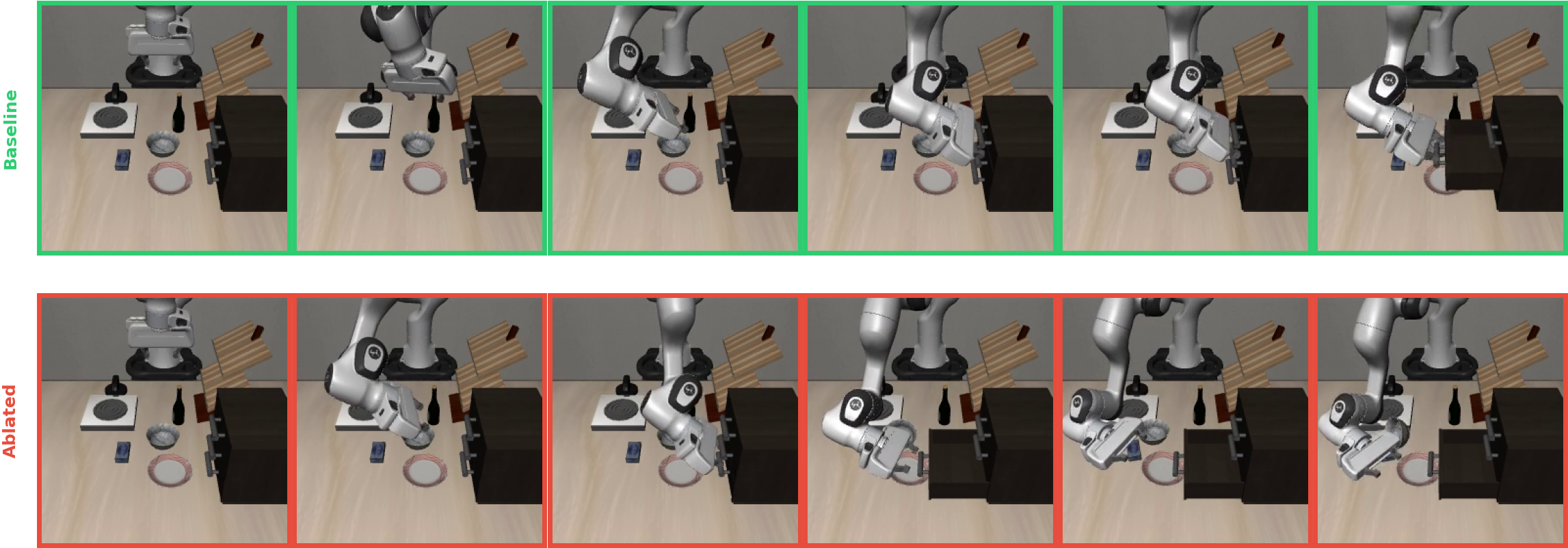
OPEN concept ablation (L8): “Open the middle drawer of the cabinet.” Top: baseline reaches for the middle drawer, grasps and pulls it open (140 steps). Bottom: with OPEN features zeroed, the robot opens the bottom drawer instead of the middle, misdirecting the motor program to the wrong target (300 steps, task failure).
Five VLAs and one language-free control, 80M to 7B parameters, three action generation paradigms
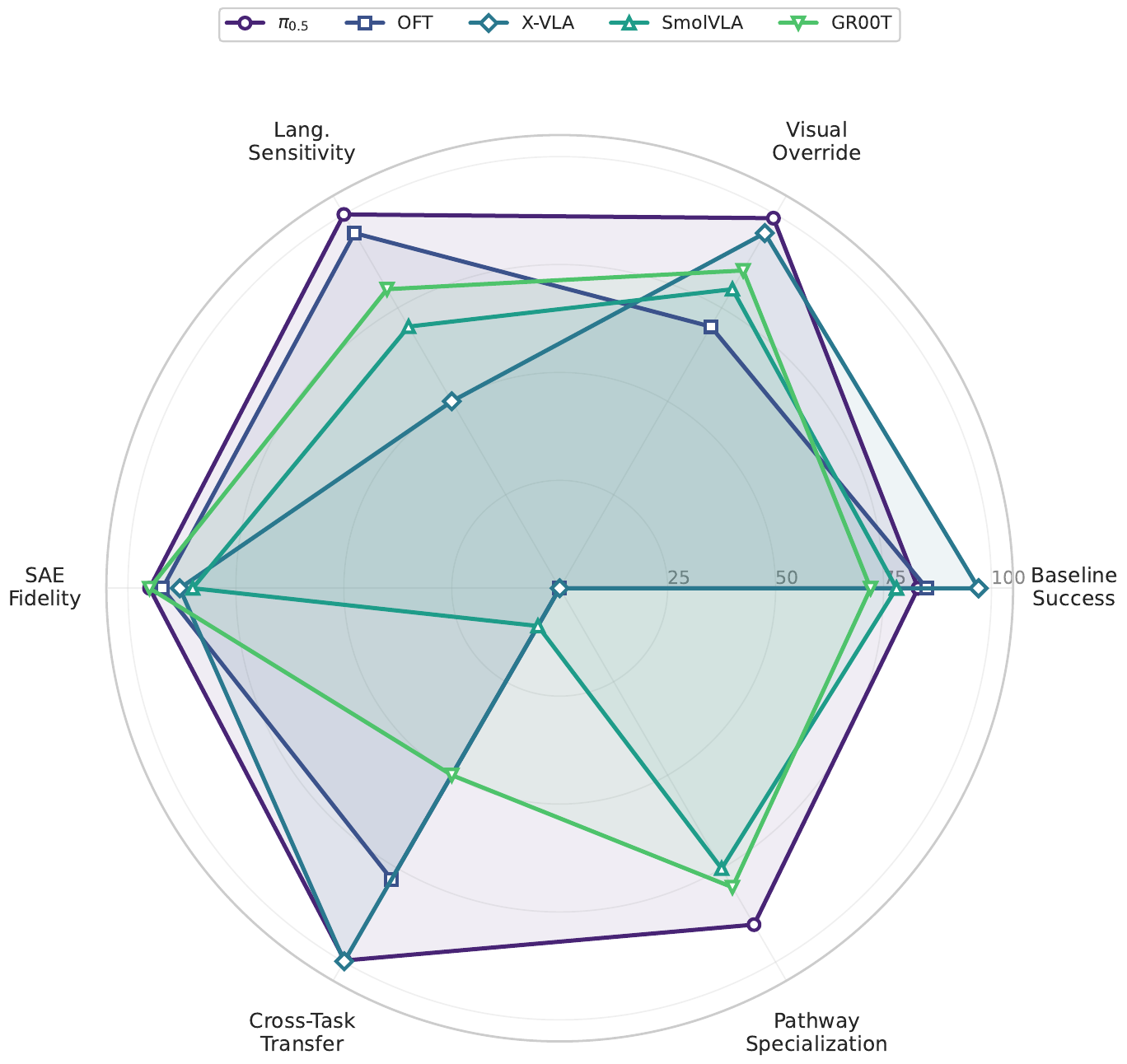
Cross-model capability radar. Five VLAs scored on baseline success, visual override strength, language sensitivity, SAE fidelity, cross-task transfer rate, and pathway specialization. OpenVLA-OFT lacks pathway specialization (single-pathway architecture); SmolVLA and GR00T show the strongest pathway specialization alongside π0.5.
4 suites, 40 tasks
MuJoCo tabletop
10 tasks, 2 embodiments
WidowX + Google Robot
Bimanual tasks
TransferCube, Insertion
50 manipulation tasks
Multi-task evaluation
| Model | Episodes | SAEs Trained | Concepts ID'd | Benchmark(s) |
|---|---|---|---|---|
| π0.5 | 71,500+ | 72 | 43 | LIBERO |
| OpenVLA-OFT | 70,700+ | 96 | 45 | LIBERO |
| X-VLA | 50,000+ | 120 | 82 | LIBERO, SimplerEnv |
| SmolVLA | 58,000+ | 146 | 45 | LIBERO, MetaWorld |
| GR00T N1.5 | 164,700+ | 87 | 36 | LIBERO |
| ACT | 1,870 | - | - | ALOHA |
| Total | 420,000+ | 520+ | 79 unique | 4 benchmarks |
Interactive visualization platform for VLA interpretability, inspired by Neuronpedia
UMAP scatter plots of 4,096+ SAE features with semantic search via SBERT embeddings
Architecture diagrams showing information flow and concept density across transformer layers
308,000+ rollout videos filterable by model, suite, experiment type, and outcome
Side-by-side baseline vs. ablated behavior with success comparison
Vision perturbation results across models with displacement analysis and cross-embodiment data
action-atlas.com
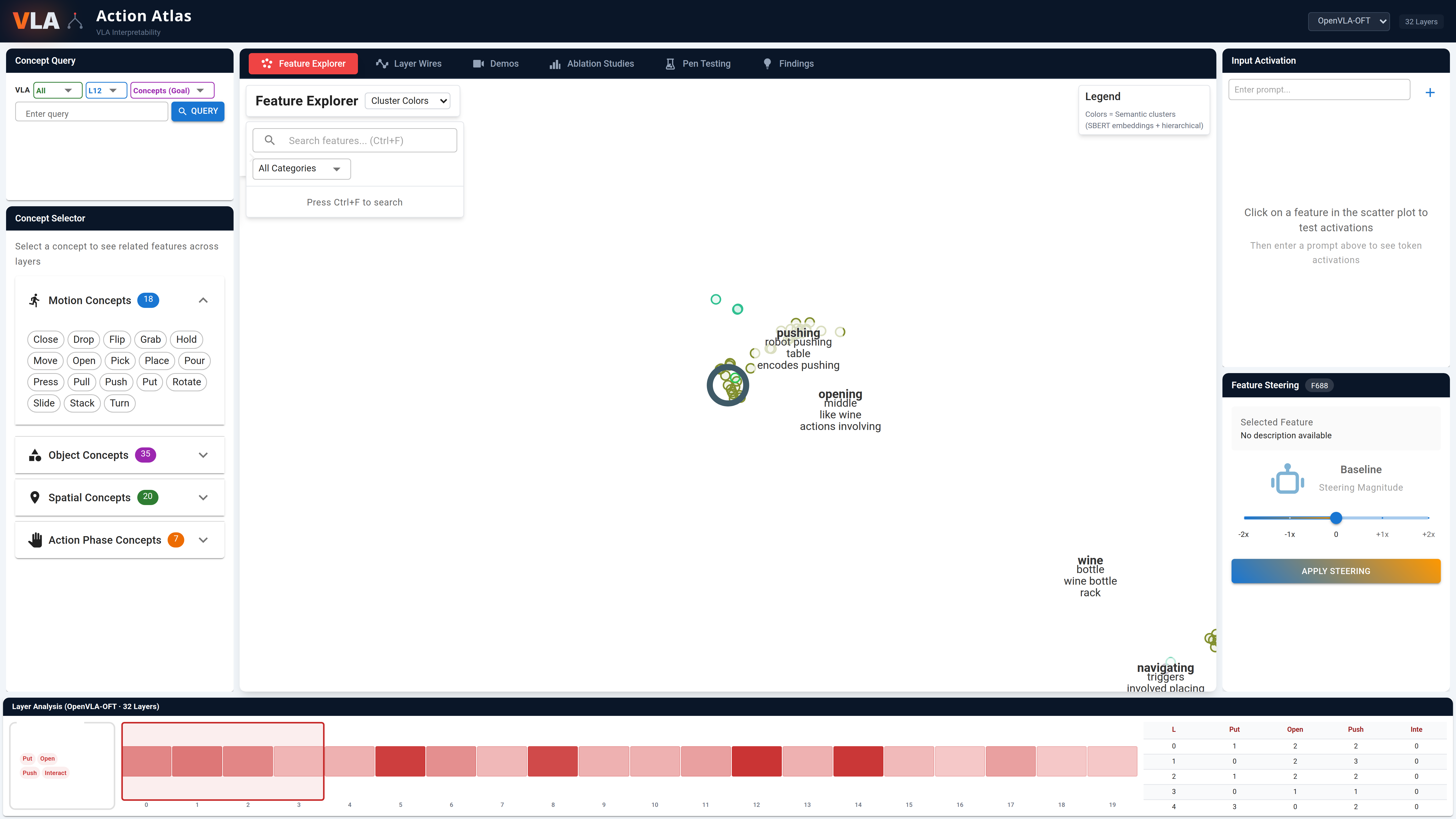
Feature Explorer
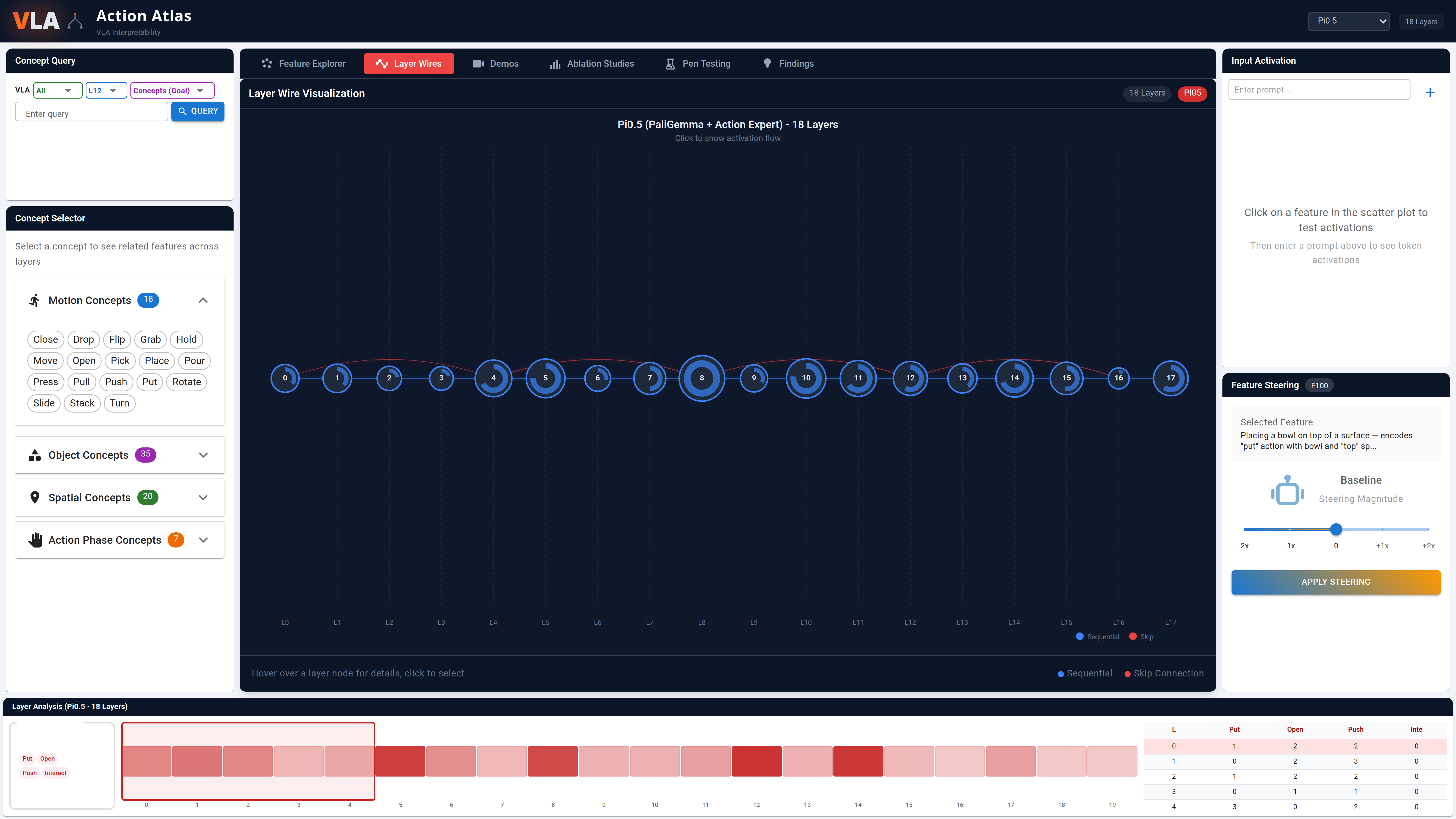
Layer Circuits
Ablation Studies
Demo Videos
@misc{grant2026featurescreatedequalmechanistic,
title = {Not All Features Are Created Equal: A Mechanistic
Study of Vision-Language-Action Models},
author = {Bryce Grant and Xijia Zhao and Peng Wang},
year = {2026},
eprint = {2603.19233},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2603.19233}
}