Composing the score
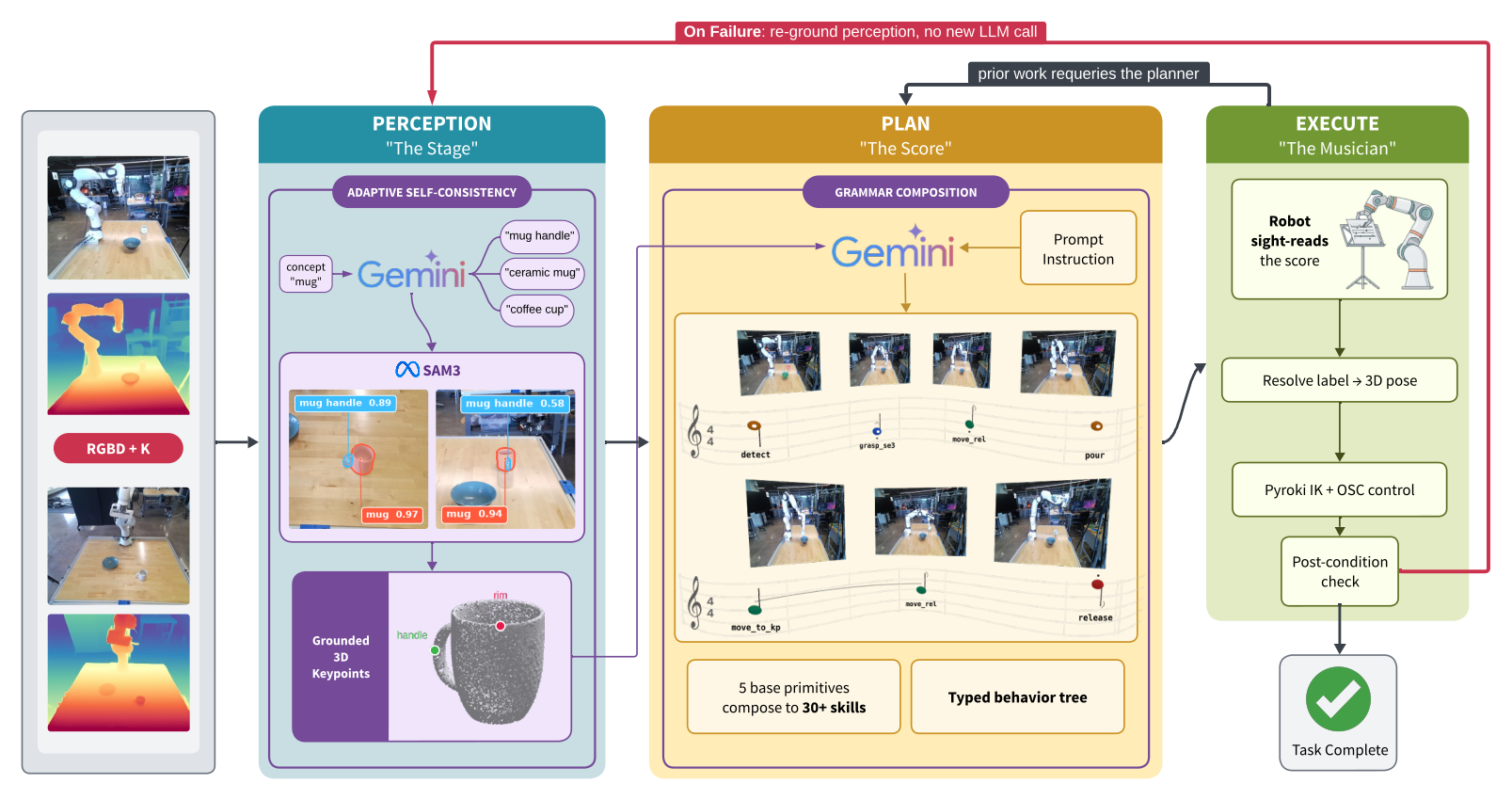
SAM3 grounds the scene from the platform cameras. One Gemini call writes the whole plan as a typed behavior tree, the score, and the robot sight-reads it without any training. The plan is symbolic, so moving an object or rewording the instruction barely changes it. “Put the bowl on the plate” calls for the same score whether the bowl starts on the left or the right. Only the pixels that the label bowl binds to have moved. Perception is the layer that breaks under that shift, so that is where SPARK spends its compute.
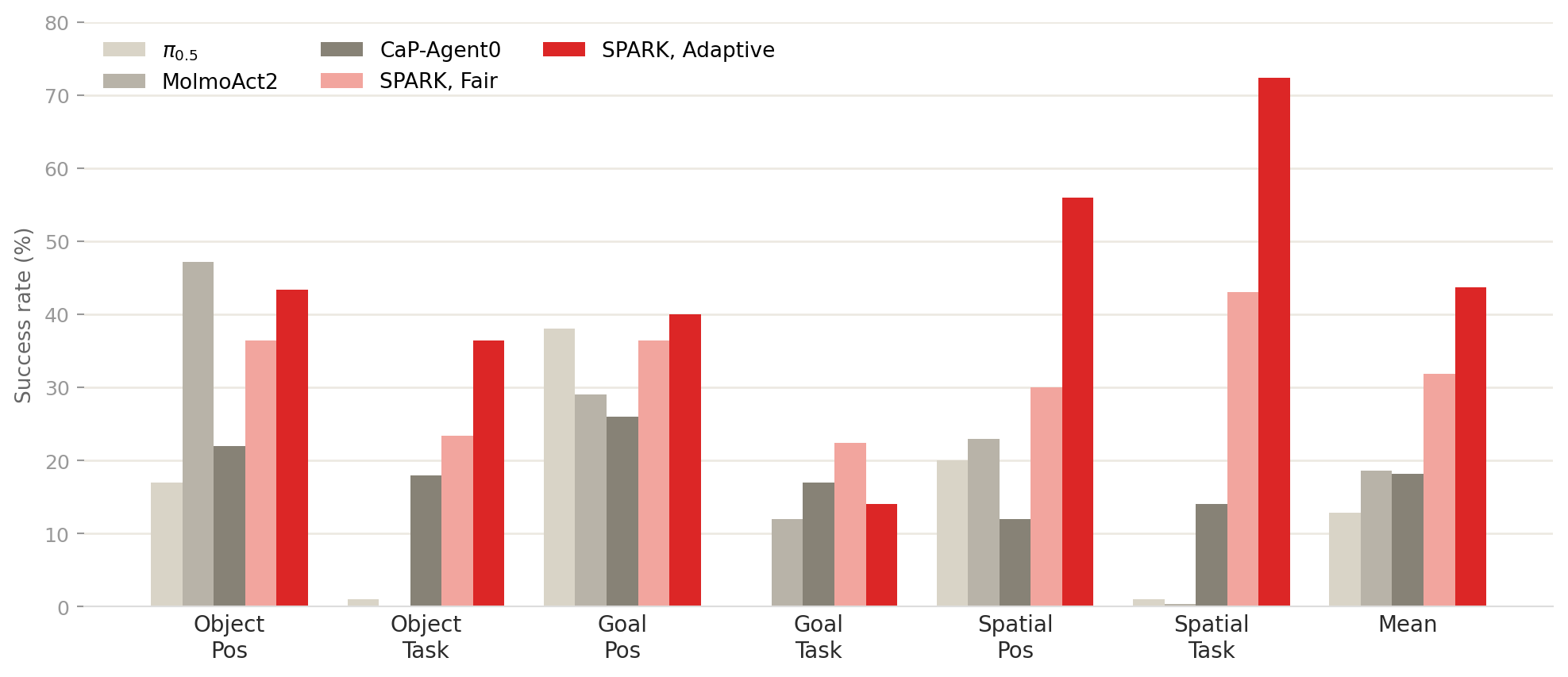
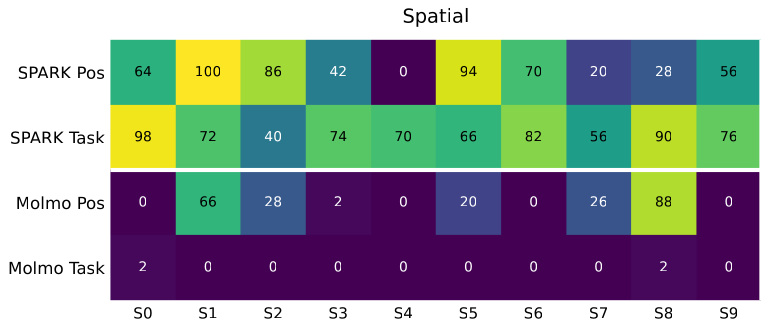
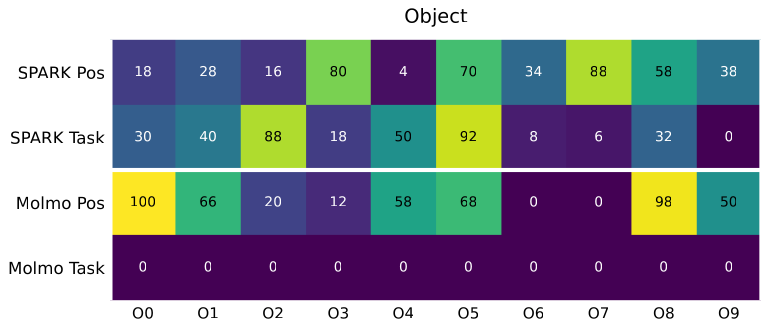
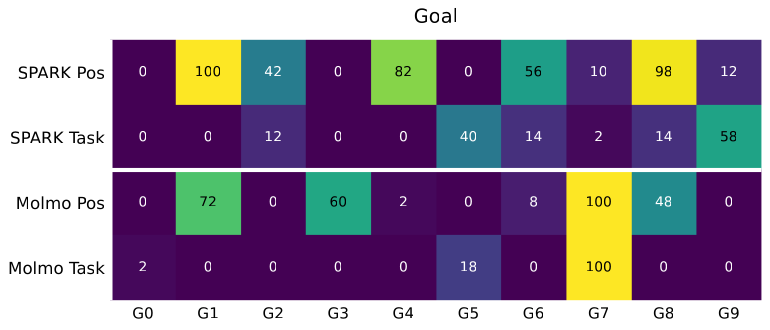
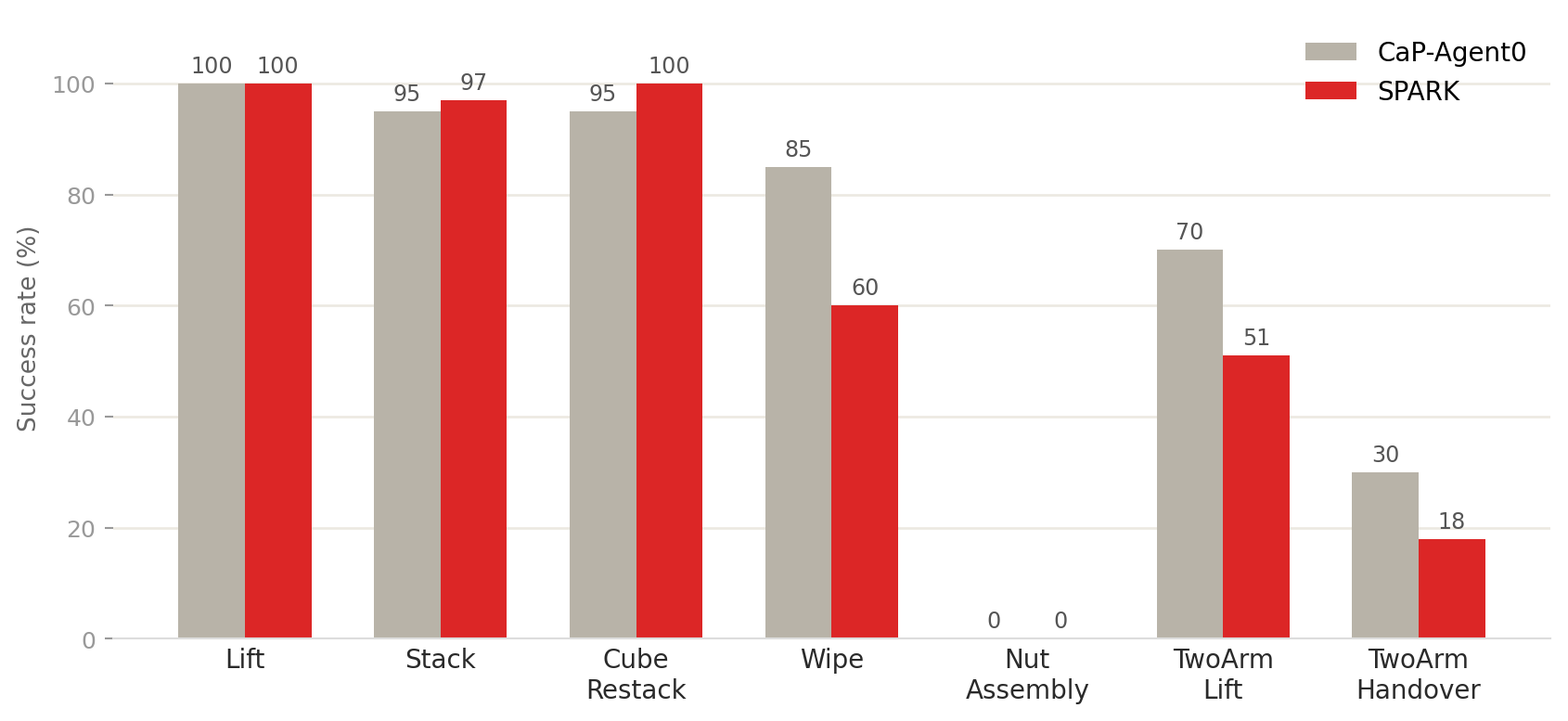
Each spatial argument is a keypoint label that the executor resolves to a 3D pose against live perception at the moment the robot acts. When a primitive’s post-condition fails, SPARK retracts, re-renders, re-runs SAM3, and retries the same plan with no new LLM call. The plan structure stays fixed while the spatial bindings are corrected. In simulation, a single extra call proposes three text prompts per object and keeps the cleanest SAM3 detection, which raises the spatial mean by 27.7 points and the object mean by 10.0. Five base primitives compose into the multi-step behaviors, and the grammar wraps those same primitives in more than thirty typed skills that add the force calibration and retry logic. Because execution flows through that grammar, every trial logs a labeled episode: trajectories for the policies that fail under these shifts, collected with no teleoperation.